
안단테 안단테
1. HBase란? 본문
1. HBase란?
빅데이터에 관심이 있는 사람들은 한번쯤 hadoop, hbase라는 단어를 들어봤을 겁니다.
저는 아마 이쪽으로 공부를 계속 해나아거 같고... 제가 공부한 내용을 하나하나 정리해볼 예정입니다!.
굵직 굵직 하게 HBase란 무엇인가 먼저 정리를 해보려고해요~
HBase는 용량이 큰 데이터에 대해서 온라인으로 처리해주는 빅데이터 처리를 이용할때 아주 좋은 도구?? 중에 하나입니다.
랜덤하게 액세스 하는것과 업데이트가 즉각적이며, 컬럼기반, 동적스키마 MapReduce Join, 확장 가능한 데이터 저장소이고, Hadoop 분산파일 시스템(HDFS) 상의 데이터 위에서 동작을 하게 됩니다.
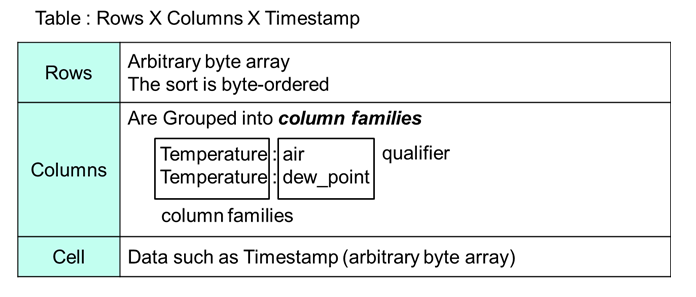
HBase에 어떻게 저장 되는지 한 번 확인을 해보겠습니다. 위에 그림 처럼 HBase는 되어 있습니다.
Table - Row들의 집합이며 schema 정의서 column Family만 정의 해줍니다.
Row key - 임의의 Byte열로 사전순으로 내림차순으로 정렬됩니다. 빈 Byte 문자열은 테이블의 시작과 끝을 의미합니다.
Column Family - Column들의 그룹, member는 같은 접두사를 사용합니다.
cell - Row key & Column & Version이 명시된 tuple입니다. 값은 임의의 Byte열입니다.

전체 테이블이 어떻게 구성되어있나 도식화 해서 설명해드리겠습니다.
앞서 말한 로우들의 집합은 리전이라 불립니다. (리전은 이 다음에 바로 설명해드리겠습니다)
로우들의 집합은 테이블이여서 로우키, 컬럼패밀리, 타임스탬프로 구성이 되어있습니다.
테이블에서 로우키로 정렬이 되고 컬럼으로도 정렬이 됩니다.
타임스탬프는 값이 작은게 최신으로 업데이트 한 값 입니다.
그리고 이런 로우들로 구성되있는 리전들을 전체 통틀어서 하나의 테이블로도 볼 수 있습니다.
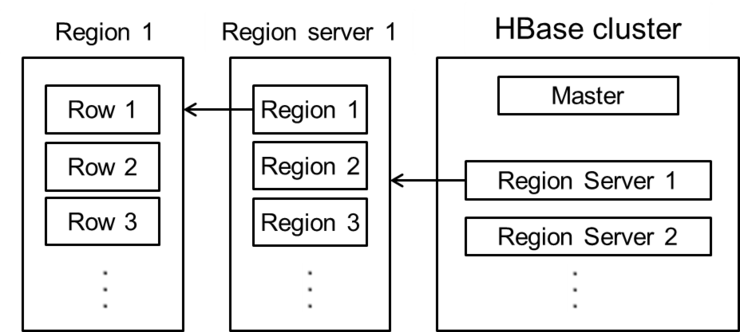
그리고 리전이란게 있습니다.
테이블은 hbase에 의해 리전으로 자동 수평 분할됩니다.
각 리전은 테이블 로우의 부분 집합으로 구성된다.
리전은 자신이 속한 테이블 이름에, 첫 번째 로우를 포함하고 마지막 로우는 빼고 표현합니다.
리전은 hbase 클러스터 상에서 분산되는 단위입니다.
(한 대의 서버로는 수용이 힘든 큰 테이블이라도 다수 서버로 이루어진 클러스터에서는 수용 될 수 있으며, 각 서버는 테이블의 전체 리전 중 일부분을 담당하게 됩니다. 이는 또한 테이블 상의 적재를 분산시키는 방법입니다.)
처음에는 테이블에는 오직 한개의 Region만 있고 Region이 row들이 추가되어 너무 커지면, Region 은 적당히 반으로 가르는 중간 키를 이용해서 나눠지게 됩니다.
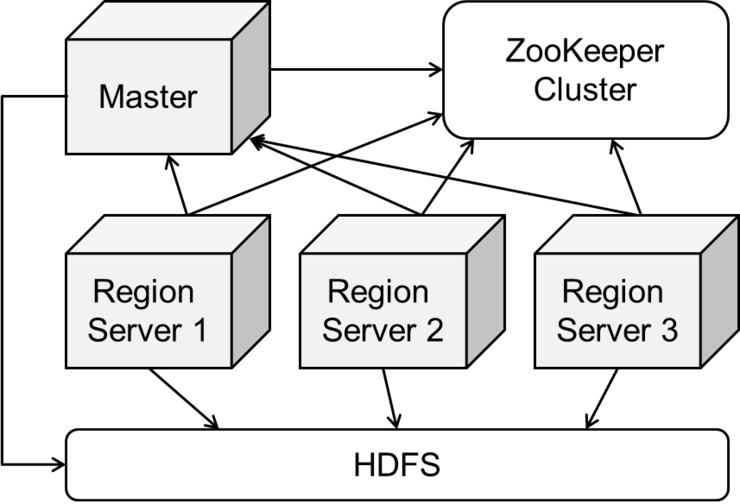
HBase는 ZooKeeper에 의존적이며 ZooKeeper 인스턴스를 사용하여 전반적인 클러스터의 상태를 관리합니다.
Hbase는 루트 카탈로그 테이블과 현재 클러스터 마스터의 주소같은 핵심적인 내용을 보유합니다.
(주키퍼 멤버쉽에 참여한 서버들이 할당 중에 고장 날 경우, 리전들의 할당은 주키퍼를 통해서 중재됩니다.)
(주키퍼 내에서 할당 트랜잭션 상태를 유지하면, 고장난 서버가 멤버쉽에서 떠나는 시점에 할당에 관한 복구가 수행되게 할 수 있습니다.)
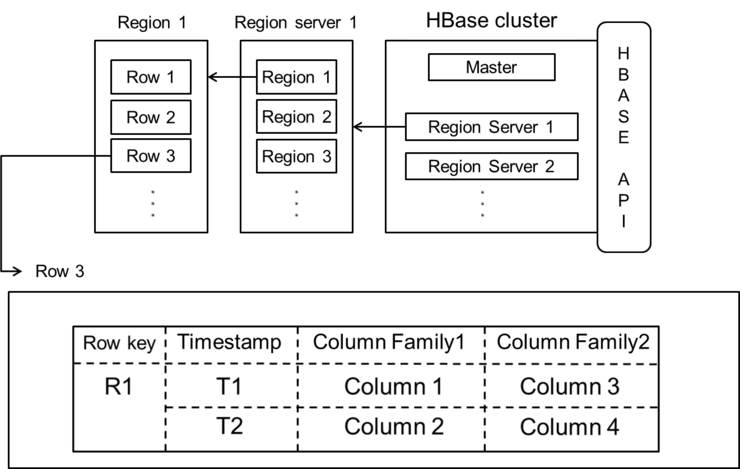
Hbase cluster에는 하나의 마스터와 리전서버로 구성되어있고
리전서버는 각 리전들로 구성되어있습니다.
리전은 로우들로 구성되어 있고 로우를 확인해보면 로우키, 타임스탬프, 컬럼 패밀리로 구성되어있고
로우들이 모여 테이블을 구성합니다.
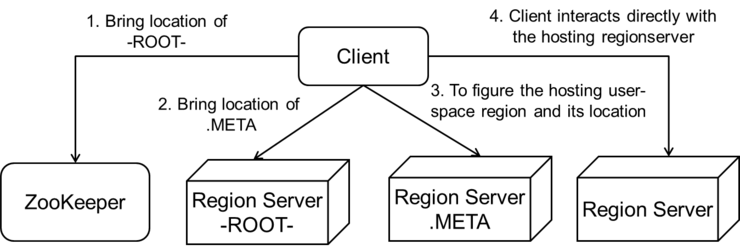
만약에 client가 특정 로우를 소유한 리전을 찾을려면
먼저 주키퍼로가서 –root-위치를 가져옴니다.
클라이언트는 요청된 로우 키를 영역 내에 있는 .meta리전 위치를 도출하기 위해 -root-로 갑니다.
.Meta로가서 사용자 공간의 리전을 관리하는 서버와 위치를 파악합니다.
이후에 클라이언트는 해당 리전 서버와 직접 상호작용 합니다.
로우 동작 당 3회 왕복 통신(round-trip) 부담을 줄이기 위해 캐싱해서 임시저장합니다.
실패하지 않고 동작할 때까지 클라이언트는 캐싱된 엔트리를 계속 사용합니다.
리전이 이동할 경우(실패) .meta와 –root-를 재참조합니다.
HBase의 장점은 데이터 일관성을 보장하고, 데이터 압축이 효율적이며 이전 버전의 데이터 값 관리가 가능하며, 한 행에 대한 atomic 처리를 가능하게 해주는 좋은 장점이 있습니다.
하지만 장점이 있으면 단점도 있기 마련인데 전체적인 구조를 알아야 하기 때문에 이해하기가 어렵고 특정 범위의 key값에 저장 요청이 집주오디는 경우 문제가 발생하게 됩니다.
지금까지 HBase에 대해서 알아봤는데 저도 계속해서 공부를 해나아가야 겠습니다.
지금까지 'HBase란'에 관한 포스팅이였습니다.
감사합니다.
'IT 기술 > BigData' 카테고리의 다른 글
| 4. java 에러 (0) | 2023.02.03 |
|---|---|
| HBase 에러종류 (0) | 2023.02.03 |
| 4. 하둡 hdfs 명령어 정리 (0) | 2023.02.03 |
| 3. Hadoop 2.2 Installation `.' no such file or directory (0) | 2023.02.03 |
| 2. Hadoop 관련 용어 정리 (0) | 2023.02.03 |