
안단테 안단테
[BigData] 리눅스 환경에 hadoop(하둡) 설치 및 구성 본문
1. 하둡(Hadoop) 설치 Hadoop / Big Data
1. 하둡(Hadoop) 설치
안녕하세요. 정말 오랜만에 포스팅을 하는거 같습니다. 요새 바쁜척좀 하느라 그랬구요. 오늘부터 시간될때마다
하둡에 관한 정보를 포스팅하겠습니다 ㅎㅎ. 저도 공부하는중이라 모르는부분이 너무나 많아요.. (이해부탁드려요)
아파치 하둡(Apache Hadoop, High-Availability Distributed Object-Oriented Platform)은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 자유자바 소프트웨어 프레임워크이다. 원래 너치의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬의 하부 프로젝트이다. 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS: Hadoop Distributed File System)과 맵리듀스를 구현한 것이다. --- 위키백과를 참조했습니다 ----
하둡을 사용하게되면 분산으로 대용량의 자료를 빠르게 처리할 수 있다는 장점이 있습니다.
하둡을 공부하려면 먼저 하둡을 설치해야겠죠?? 그러면 지금부터 설치법에 대해서 알아보겠습니다.
저는 Cent OS 6.4버전에 하나의 마스터와 2개의 슬레이브 구조로 완전 분산 모드로 설치를 하였습니다.
(만약에 Standalone모드를 설치하려면 11번의 하둡경로/conf에서 hadoop-env.sh만 변경하고 나 머지는 건드리지 않는다.)
1. jdk 설치
하둡은 자바로 되어있기때문에 자바 1.6 버전이상을 설치해야 됩니다.
(필자는 /usr/local/java 에다 설치를 하였다. 기본적으로 설치를 하면
/usr/java/jdk1.7.0_45에 설치가 될텐데 이걸 /usr/local/java로 옮겨서 설정을 해주는게 좋다. 왜냐하면 제가 한 경로나 뭐든 것들이 다 /usr/local/java 이기 때문이다 ^_^)
- yum install java-1.7.0-openjdk-devel
- wget http://mirror.its.sfu.ca/mirror/CentOS-Third-Party/NSG/common/x86_64/ 자기가 원하는 파일
2. 자바설치경로에서
rpm -ivh jdk-7u45-linux-x64.rpm
만약 jdk버전을 새로 받고 싶다 그러면 지웠다가 다시 깔면 된다
지우는방법 (먼저 jdk 버전을 확인하자
rpm – qa | grep java
이렇게 치면 java-1.x.x-open~~~~ 이런게 있을 것이다.
yum remove java-1.x.x-open~~~~을 쳐주면 제거)
3. java 확인 (한글이 깨져서 보일 수도 있습니다.)

4. javac 확인

5. java –version 확인

위에 세가지가 정상적으로 나오면 자바는 설치가 완료 되었습니다.
이제 본격적으로 하둡을 다운로드 하겠습니다.
6. hadoop 다운로드
- wget http://archive.apache.org/dist/hadoop/core/hadoop-x.y.z/ 원하시는 파일을 받으시면 됩니다.
7. hadoop 압축 해제
- tar xvfz hadoop-1.0.3.tar.gz
만약에 symbolic link를 걸어주고 싶으면 ln –s hadoop-1.0.3 hadoop
확인은 ls –l로 해준다.
하둡의 설치는 그냥 받고 압축만 해제하면 쉬운데 환경설정들이 많습니다.
이제부터 환경설정을 해야되니 마음 단단히 잡으시고!!!! 참고하세요 ㅎㅎ
8. hosts설정 (master 와 slave)
vi /etc/hosts
자신의 아이피 주소 master
(ex 166.104.242.56 masters)
자신의 아이피 주소 slave
(ex 166.104.242.58 slaves01)

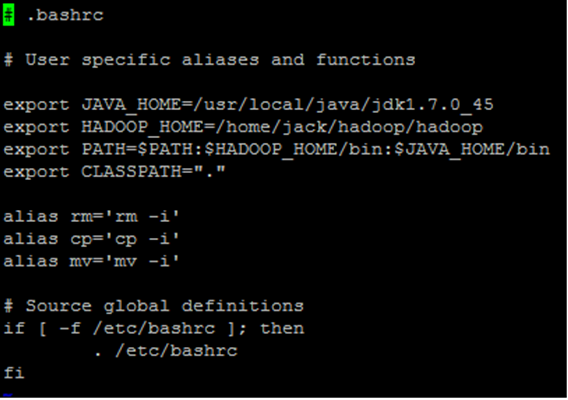
9. 환경설정 (공백 없이 설정해줘야됨 export에서 한 칸 띠고 그다음부턴 공백없음)
- vi ~/.bashrc
export JAVA_HOME=/usr/local/java/jdk1.7.0_45 (자신의 jdk경로와 버전)
export HADOOP_HOME=/home/jack/hadoop/hadoop(symbolic link)
(자신의 하둡 설치 경로)
export PATH=$PATH:$HADOOP_HOME/bin:$JAVA_HOME/bin
export CLASSPATH=“.”
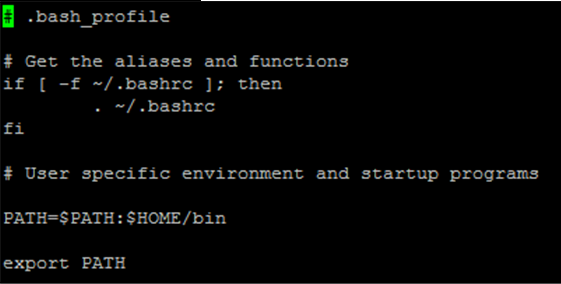
- vi ~/.bash_profile (아마 이건 바꿀게 없을 것이다.)
PATH=$PATH:$HOME/bin
export PATH
- vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.7.0_45 (자신의 jdk경로와 버전)
export PATH=$PATH:JAVA_HOME/bin
export CLASSPATH=“.”

10. 하둡 실행을 위한 ssh키 분배
ssh 키 분배를 해야 암호입력없이 사용을 할 수 있습니다.
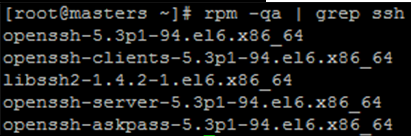
ssh 설치
yum -y install openssh-server openssh-clients
ssh 설치 확인
rpm -qa | grep ssh

----- cd /home/jack/hadoop/hadoop(자신의 하둡 경로)/conf 에서 설정할것들 ---------
여기가 가장 중요한 부분입니다. 오타가 있으면 안되고 자기 컴퓨터 환경에 맞게 설정해야 되니 참고 부탁드리겠습니다.
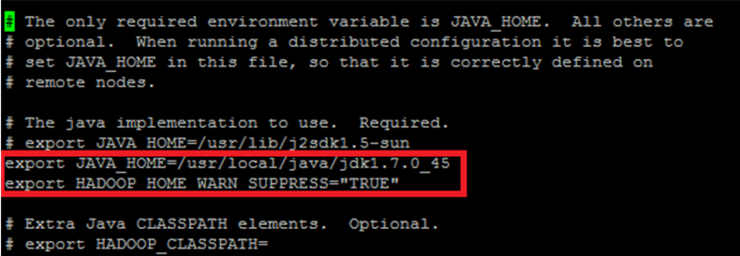
11. hadoop-env.sh 설정
(만약에 Standalone모드를 설치하려면 하둡경로/conf에서 hadoop-env.sh만 변경하고 나 머지는 건드리지 않는다. 이 설치법은 fully distributed mode를 기준으로 변경한 것이다.)
vi hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.7.0_45(자신의 jdk경로)
export HADOOP_HOME_WARN_SUPPRESS="TRUE" (하둡 경로를 symbolic link 하였을때 hadoop을 실행하면 warring이 뜨는데 그것을 방지)
12. core-site.xml 설정
vi core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://(master의 ip adress):9000</value>
</property>
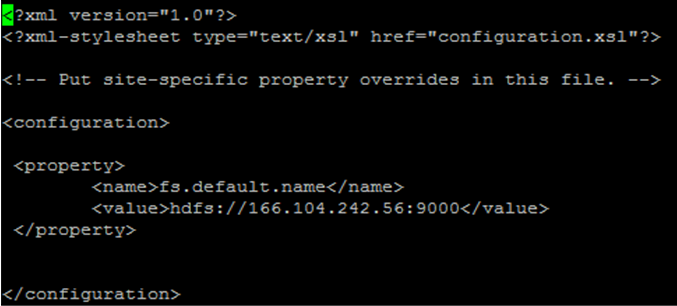
마스터의 호스트 아이피 주소말고 그냥 호스트명을 써도 된다고 하는데 쓰면 하둡을 실행할 때 아래와 같은 에러를 볼 수 있을 것이다. 이것을 방지하려고 호스트 주소를 사용한다.

13. hdfs-site.xml 설정
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hdfs/name/</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hdfs/data/</value>
</property>
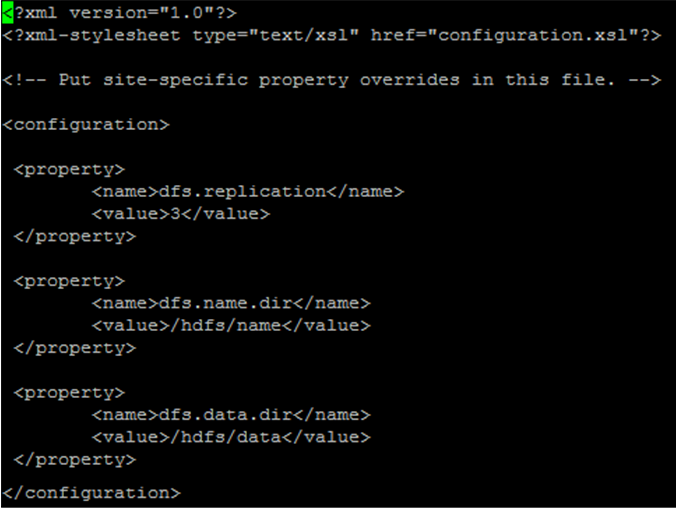
14. mapred-site.xml 설정
vi mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>hdfs://(master의 ip adress):9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/hdfs/mapreduce/system</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/hdfs/mapredcue/local</value>
</property>
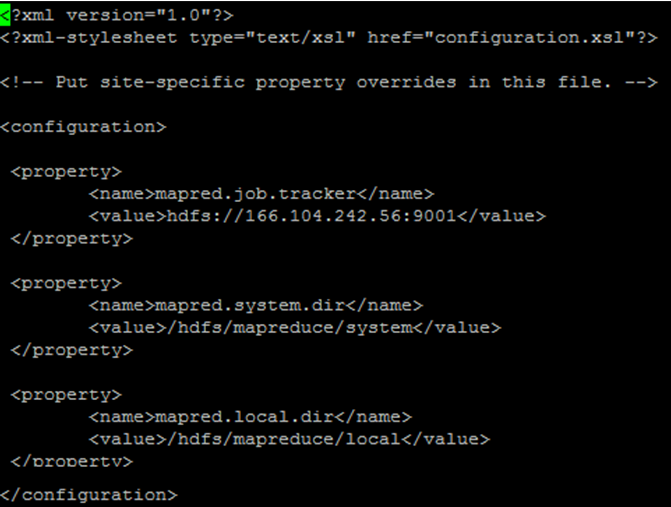
15. SecondaryNamenode 설정 (모든 master, 모든 slave에서 실행)
vi masters
masters
16. slaves 설정 (모든 master, 모든 slave에서 실행)
vi slaves
slaves01
slaves02
17. 하둡 실행 & 확인
경로가 설정되어 있으면 어느곳에서든 가능하지만 경로를 설정 안하였다면 /hadoop/bin으로 이동한다
이건 마스터에서만 실행
./hadoop namenode -format
./start-all.sh
master에서 jps 를 치면
jps, jobtracker, namenode, secondarynamenode 가 뜰것이고
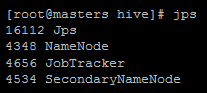
slave에서 jps 를 치면
jps, datanode tasktracker 가 나올것이다
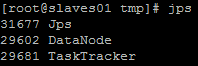
여기까지 문제 없이 설정을 잘 적용하였다면 정상적으로 작동이 될 것입니다.
하지만 오타, 자기 환경에 맞지 않게 설정이 되면 에러가 뜨기 마련입니다.
다시 한번 확인해주시고 만약 안되시는점 있으시면 제가 아는 범위내에서 최대한 많이 알려드리겠습니다.
지금까지 하둡 설치에 관한 포스팅이였습니다.
감사합니다.
'IT 기술 > BigData' 카테고리의 다른 글
| 머하웃 완벽 가이드) - 8장 벡터 생성기 (0) | 2023.02.02 |
|---|---|
| 머하웃 완벽 가이드) - 7장 클러스터링 예제 (0) | 2023.02.02 |
| [BigData] Hadoop(하둡) hdfs 명령어 정리 (0) | 2022.03.05 |
| [BigData] Hadoop 2.2 Installation `.' no such file or directory (0) | 2022.03.05 |
| [BigData] 하둡(hadoop) 용어 정리 (0) | 2022.03.05 |